Seatunnel测试

1. 前置条件
- seatunnel
- hadoop,检查点会用到hdfs,没有也能看到效果
- 本地hadoop,需要hadoop_home,没有也能看到效果
2. sftp->hive
2.1 场景说明
将ftp文件同步到hive分区表中,根据ftp文件内容字段动态保存。
2.2 准备
环境准备
- seatunnel-2.3.1
- hadoop-3.3.2
- hive-3.1.2
- sftp服务器
ftp文件内容
1 | user_id#user_name#create_time#province_id |
- hive建表sql
1 | create table if not exists user_info( |
2.3 seatunnel配置文件编写
1 | env { |
2.4 多种方式加载数据到hive
- 上传数据到指定分区目录后修复,将没有创建分区的目录创建对应分区
1 | msck repair table user_info; |
- 事先/是否创建分区即可
1 | alter table user_info add partition(province_id='11',create_day='2023-06-23'); |
- 手动执行load语句load数据
1 | load data inpath 'hdfs://192.168.10.222:9000/hive/warehouse/dev.db/user_info/province_id=11/create_day=2023-06-23/ T_724967131367604225_a452435c6e_0_1_2023.06.24_0.txt' into table user_info partition(province_id='11',create_day='2023-06-23'); |
2.5 执行结果
hdfs结果
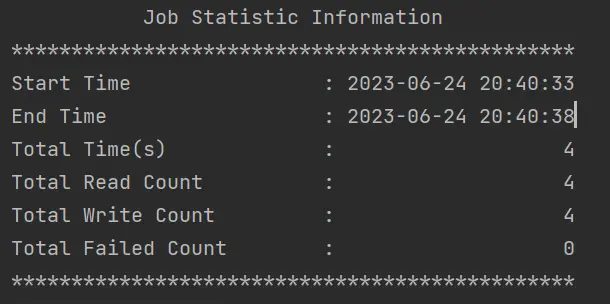
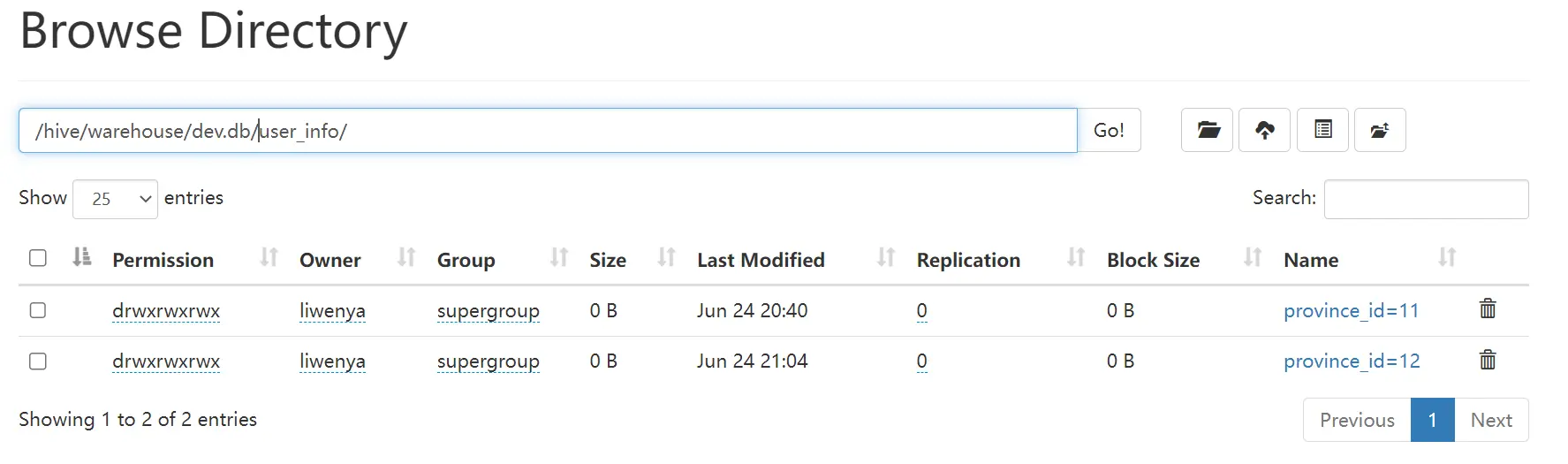
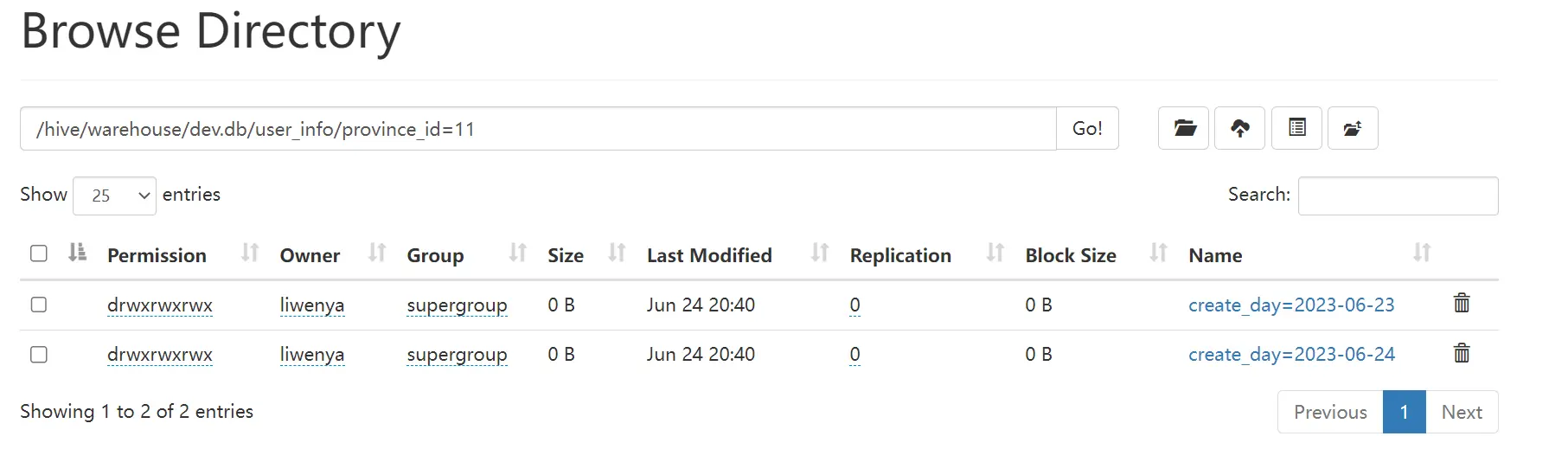
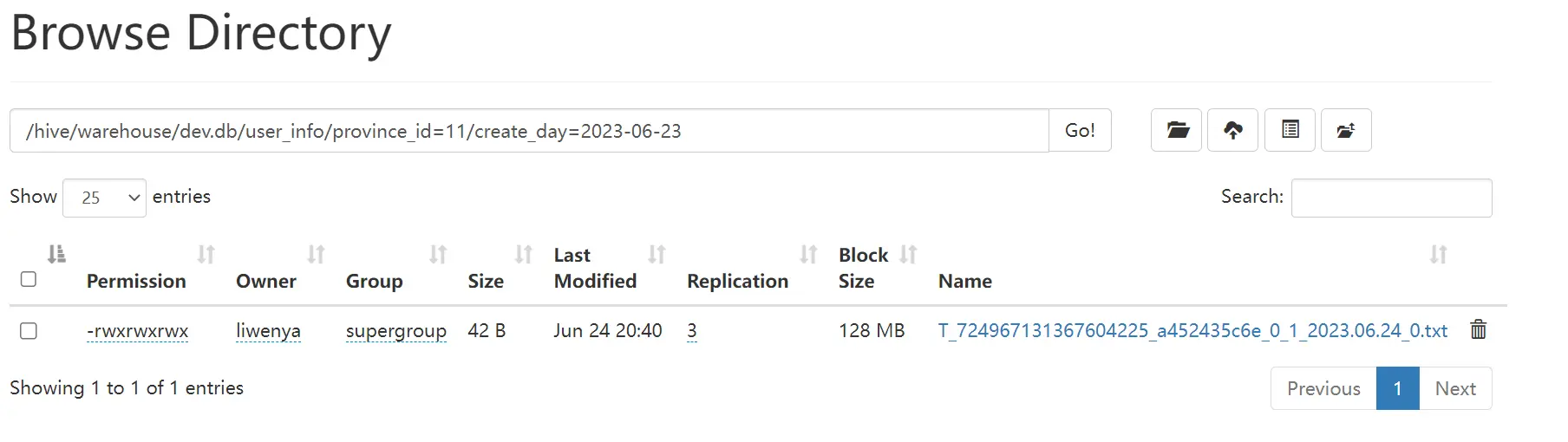
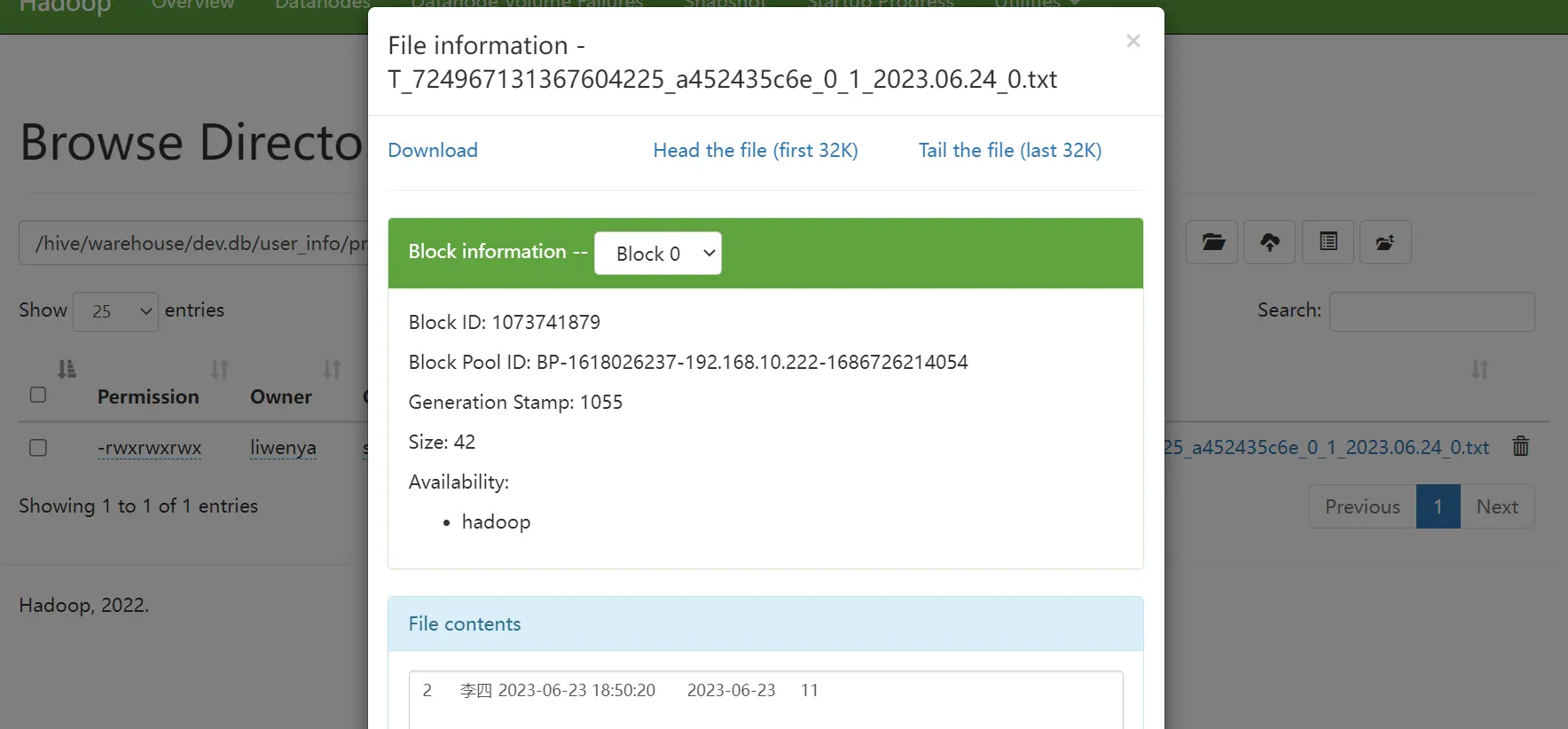
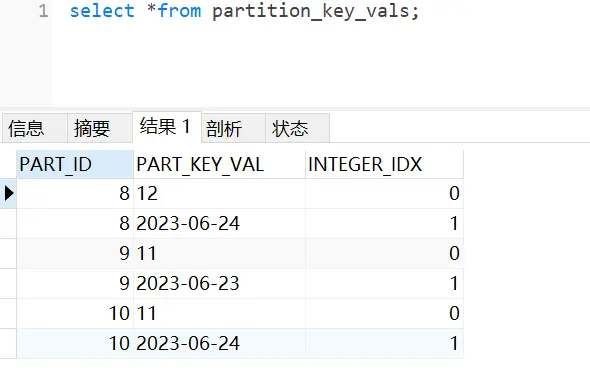
- hive查询结果

3. kafka->hive
3.1 场景说明
将kafka队列数据同步到hive分区表中,根据消息体字段动态保存。
3.2 准备
环境准备
- seatunnel-2.3.1
- hadoop-3.3.2
- hive-3.1.2
- kafka_2.11-0.11.0.1
kafka内容
1 | {"user_id":"1","user_name":"张三","create_time":"2023-06-24 19:59:23","province_id":"12"} |
- hive建表sql
1 | create table if not exists user_info_kafka( |
3.3 seatunnel配置文件编写
1 | env { |
3.4 发送kafka消息
- 启动zk
1 | nohup bin/zookeeper-server-start.sh config/zookeeper.properties >> zookeeper.nohup.out & |
- 启动kafka
1 | nohup bin/kafka-server-start.sh config/server.properties >> producer.nohup.out & |
- 创建topic
1 | bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic user_info_topic |
- 发送消息
1 | bin/kafka-console-producer.sh --broker-list localhost:9092 --topic user_info_topic |

3.5 多种方式加载数据到hive
同2.4
3.6 执行结果
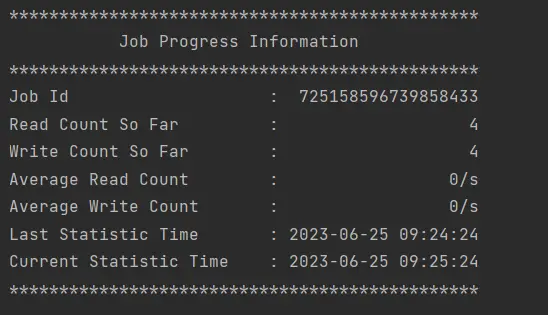
- seatunnel执行结果
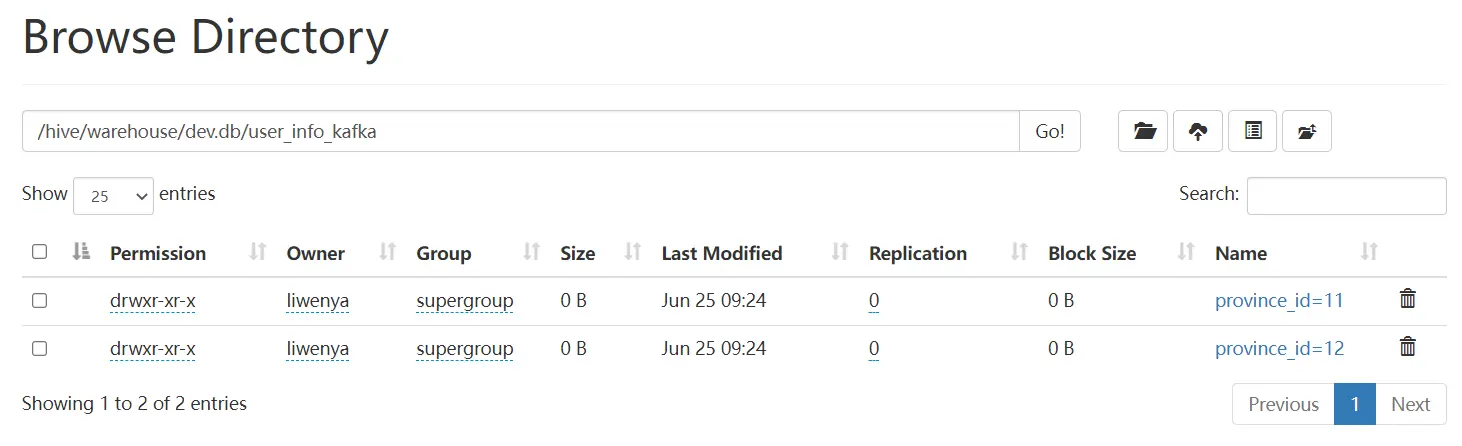
- hdfs结果
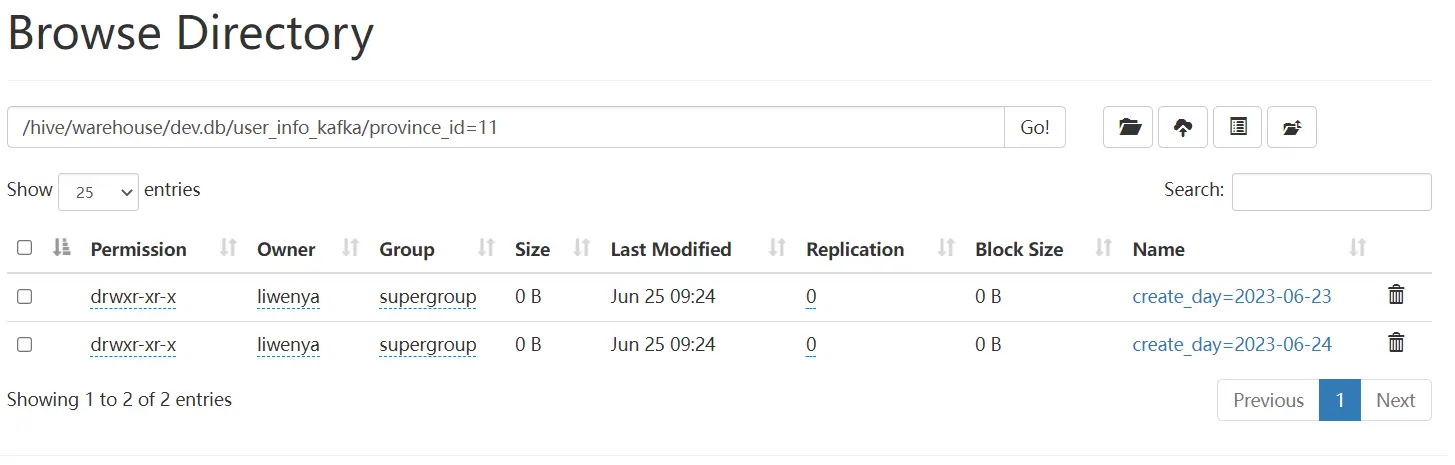
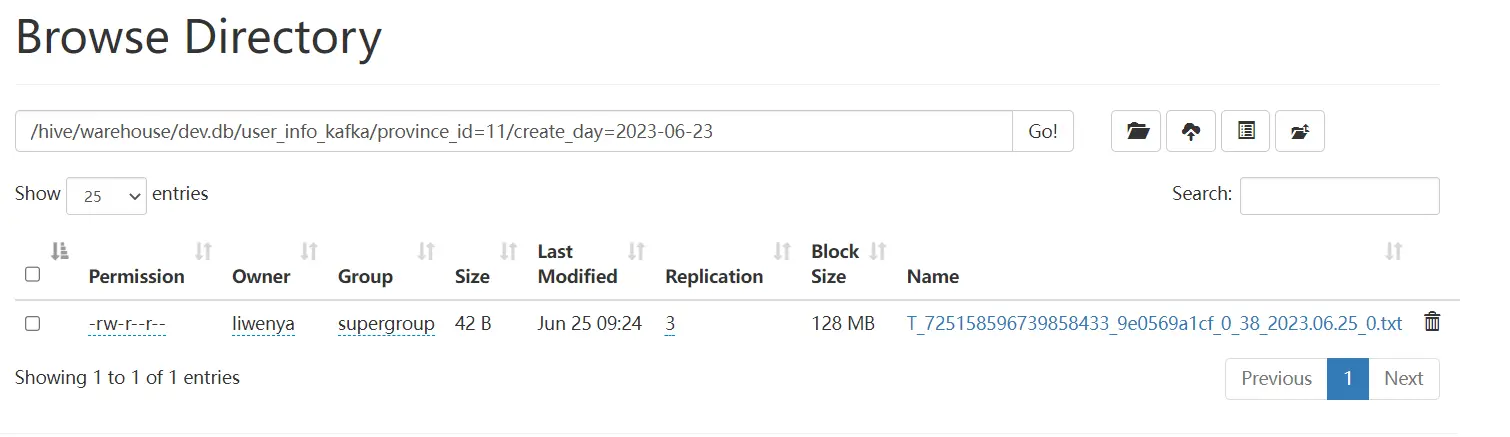
- hive查询结果

4. rdb->hive
4.1 场景说明
将关系型数据库数据同步到hive分区表中,根据消息体字段动态保存,示例选用mysql->hive。
4.2 准备
- 环境准备
- seatunnel-2.3.1
- hadoop-3.3.2
- hive-3.1.2
- mysql-8.0.32
- mysql建表sql
1 | CREATE TABLE `user_info` ( |
- mysql表内容
1
2
3
4
5INSERT INTO `user_info` (`user_id`, `user_name`, `create_time`, `province_id`) VALUES (1, '张三', '2023-06-24 19:59:23', 12);
INSERT INTO `user_info` (`user_id`, `user_name`, `create_time`, `province_id`) VALUES (2, '李四', '2023-06-23 18:50:20', 11);
INSERT INTO `user_info` (`user_id`, `user_name`, `create_time`, `province_id`) VALUES (3, '王五', '2023-06-24 19:59:23', 12);
INSERT INTO `user_info` (`user_id`, `user_name`, `create_time`, `province_id`) VALUES (4, '赵六', '2023-06-24 20:03:01', 11); - hive建表sql
1 | create table if not exists user_info_mysql( |
4.3 seatunnel配置文件编写
1 | env { |
4.4 多种方式加载数据到hive
同2.4
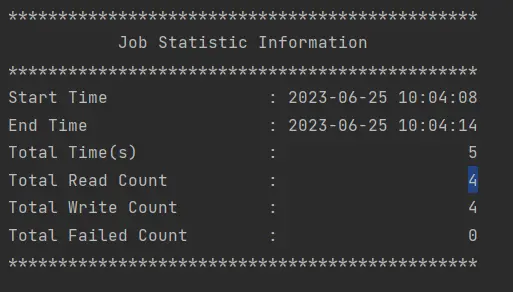
4.5 执行结果
- seatunnel执行结果
- hdfs结果
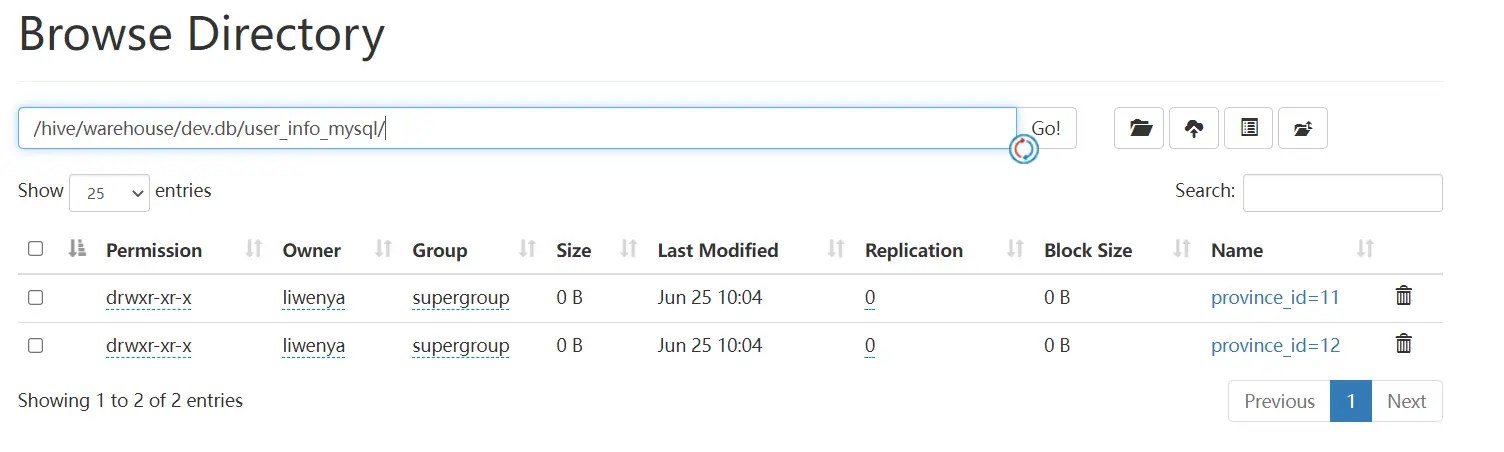
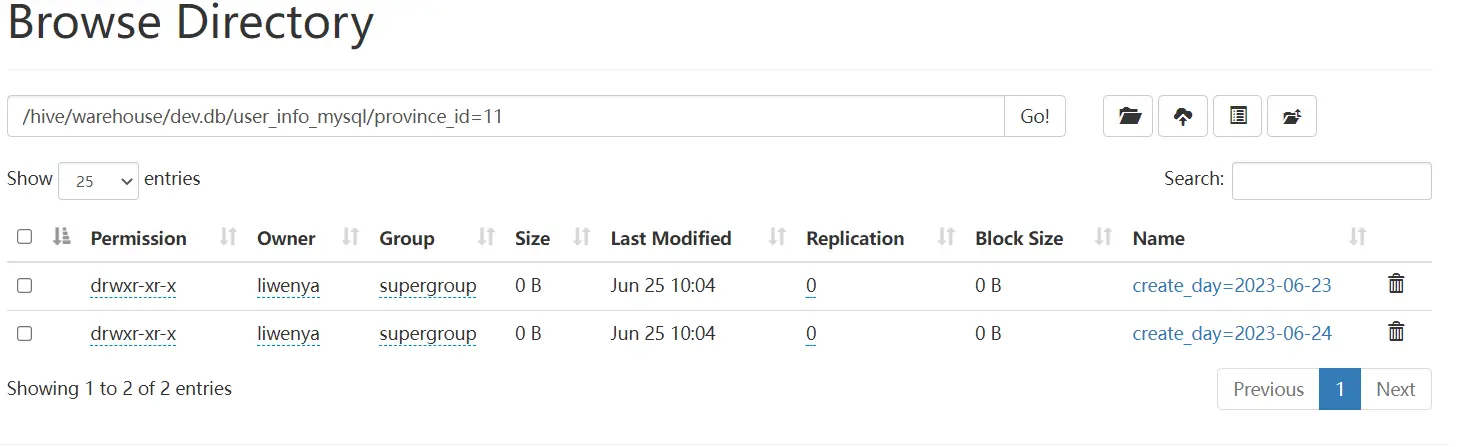
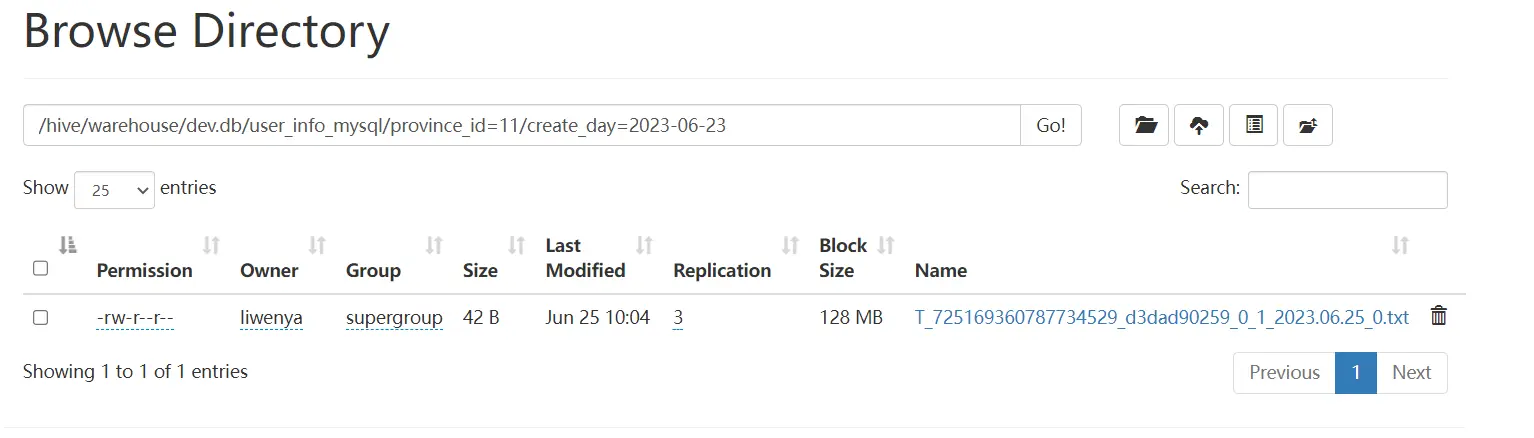
- hive查询结果

5. 结论
- 支持sftp、kafka、rdb数据源
- 支持根据字段动态分区
- kafka支持离线、实时处理
- sftp不支持增量扫描
- sftp不支持编码转换
- sftp不支持文件级check、解码、回传